面对越来越多的DNN专用处理器设计(芯片和IP),我们很自然的需要解决一个问题「怎样对不同的DNN处理器设计做出公平的比较和评价?」能不能像手机跑分一样也让它们跑个分呢?这实际是个基准测试(Benchmarking)问题。正好最近看到两个在这方面的尝试,一个是MITEyeriss团队给出的DNNProcessorBenchmarkingMetrics;另一个是百度DeepBench项目的更新。我们可以结合这两个项目讨论一下如何给DNN处理器「跑分」。
一
首先,我们还是简单回顾一下Benchmark的背景知识。以下是Wikipedia对Benchmark(computing)的定义:
Incomputing,abenchmarkistheactofrunningacomputerprogram,asetofprograms,orotheroperations,inordertoassesstherelativeperformanceofanobject,normallybyrunninganumberofstandardtestsandtrialsagainstit.Theterm'benchmark'isalsomostlyutilizedforthepurposesofelaboratelydesignedbenchmarkingprogramsthemselves.
实际上,我们非常熟悉的手机跑分也是Benchmark的一种。Benchmark通常用于评估计算机硬件的性能特征,例如CPU的浮点运算性能,GPU的图像处理能力,存储系统访问的速度等等,有时也用于软件或者编译工具。总的来说,Benchmark提供了一种比较不同软硬件系统性能的方法。从另一个角度来说,Benchmark也可以在我们自己的设计过程中帮助我们评价不同版本优化改进的情况,这可以看作是一种纵向比较。
在我们研发的过程中,会用到各种各样的测试程序。Benchmark本质上也是测试程序,它的特殊性体现在:大家公认它可以评价(一般是定量的)被测试目标的某些特性。如果不是公认的基准测试,也就谈不上横向比较的作用了。
专用的DNNProcessor(或者DNN/DL/MLProcessor/Accelerator)的研究和应用还是最近几年的事情,目前还没有大家公认的基准测试方法和指标。一个原因是,专用硬件针对特定应用(范围比较窄),一般也进行了特殊的优化,设计能够相互比较的基准测试比较困难。但是,由于AI/DeepLearning的快速发展和广阔前景,目前很多研究机构和公司都投入到专用的DNN处理器的研发当中,对比和竞争在所难免。而技术正是在对比和竞争中不断发展的,DNN处理器的基准测试已经越来越得到大家的关注。
二
MIT的Eyeriss团队无疑是DNNProcessor界一股重要的力量。他们最近搞了一个「TutorialonHardwareArchitecturesforDeepNeuralNetworks」[1],非常全面,建议同学们好好看看。这个Tutorial中有一部分就是「BenchmarkingMetrics」(基准测试指标)。
通常,我们说Benchmarking的时候一般包括两部分内容,一是测试程序(包括测试方法),即Benchmark本身;二是结果的表达(或者评价指标),即Metrics。例如,经典的Benchmark:Dhrystone,它的测试方法就是在目标处理器上运行一段精心设计的C程序:「simpleprogramsthatarecarefullydesignedtostatisticallymimictheprocessorusageofsomecommonsetofprograms」。运行这段程序实际会得到很多信息,而它采用的Dhrystonescore的表达为「thenumberofDhrystonespersecond(thenumberofiterationsofthemaincodelooppersecond)」。这里为什么不用MIPS(每秒能运行多少百万条指令)这种更常见表达呢?这是因为,对于RISC和CISC这两种不同的指令架构,在task层面统计结果要比在指令层面更为公平合理。此外,还可以用DMIPS(DhrystoneMIPS)作为指标,即Dhrystone成绩除以1757(这是当年在VAX11/780机器上获得的每秒Dhrystones的数量,名义上作为1MIPS);或者使用DMIPS/MHz,这样可以方便对比运行在不同时钟频率上的处理器。从Dhrystone的例子可以看出,对于一个成功的Benchmark来说,合理有效的测试程序和Metrics都是非常重要的。
我们回到Eyeriss的方案。应该说他们最主要的贡献在于Metrics。他们并没有专门设计「测试程序」,而是直接使用「widelyusedstate-of-the-artDNNs(e.g.AlexNet,VGG,GoogLeNet,ResNet)withinputfromwellknowndatasetssuchasImageNet」。采用「经典」的DNN网络作为Benchmark相当于用目标应用来作为测试程序,虽然比较直接,但也有很多问题。我们在本文「下篇」分析百度的DeepBench的时候再做详细讨论。
Eyeriss团队提出两个层次的Metrics。第一个是MetricsforDNNAlgorithm,主要是算法层面的指标。我们重点看第二个,MetricsforDNNHardware:
Measureenergyandoff-chip(e.g.,DRAM)accessrelativetonumberofnon-zeroMACsandbit-widthofMACs
Accountforimpactofsparsityinweightsandactivations
NormalizeDRAMaccessbasedonoperandsize
Tocomputetheoff-chipaccess,assumetheDNNprocessorisastand-alonechip.Theoff-chipaccessshouldaccountforallaccessesneededtocompleteallthelayerslistedincludinginitialinputsandfinaloutputsfromanoff-chipdevice(e.g.,DRAM).Thegoalistocomparetheoff-chipaccessatsteadystate,soaccessesduringramp-up/rampdonotneedtobeincluded(e.g.loadingconfigurationparameters,orloadingweightsif allweightscanbestoredonchip).
EnergyEfficiencyofDesign
pJ/non-zeroMAC
ExternalMemoryBandwidth
Off-chipaccess(inBytes)/non-zeroMAC
AreaEfficiency
Totalchipmm2/multiplierandstoragecapacity/multiplier
Accountsforon-chipmemory
这里列出的一些指标是非常有针对性的。它们和传统的指标,比如RunTime,Power,相结合,希望能够覆盖:Accuracy,Power,Throughput,Cost这些硬件相关的基本要素,并能够提供Externalmemorybandwidth,Requiredon-chipstorage,Utilizationofcores这些重要信息。可以看出,很多指标都非常强调效率,Efficiency,特别是对于面积和功耗这些和成本相关的指标。另外,在对DNN处理器的核心MAC做相关测试时,强调了non-zeroMAC(和稀疏性相关)以及bit-widthofMAC(和精度相关)这两个条件,反映了DNN的特点。
三
说到这里,顺便提一下我刚看到的另一个指标,来自Intel/Nervana的NaveenRao在「O'ReillyArtificialIntelligenceConference2017」上的一个讲演。也可参考[3]

他提出了ComputationalCapacity的概念,涉及的3个变量是:1)bitwidthofnumericrepresentation;2)memorybandwidth;3)OPs/s。其中:b=#bitsofrepresentation,m=memorybandwidthinGigaBits/s,o=TeraOPs/s,分母是10的6次方。这里使用精度比特数的平方作为一个简单的表达方式,在指标中考虑实现这个精度的乘法器的相对面积。即,在实际芯片中,16bit乘法器的面积大约是8bit乘法器的4倍。这个概念的提出,是因为常用的FLOPS指标已经不能准确的评价处理器的DNN处理能力了,而综合上述三个因素才是更合理的表示方法。这个指标和上述Eyeriss提出的多个指标有一定的类似之处,它的好处是比较简洁,可以用一个公式来表示,但它包含的信息也要少一些。
另外一个很有用的指标(或者叫性能评价模型)是RooflineModel[4]。通过这个model,既可以评估一个设计的效率,还能很容易看出你的设计倒底是computation-limited还是memorybandwidth-limited,可以帮助你确定进一步优化的思路.
比如Google在TPU的论文里采用这RooflineModel来和GPU,CPU进行了对比,如下图。

Rooflinemodel很好的说明了,一个好的评价模型,可以很直观的给我们展示出最重要的信息。它的玩法很多,用好了也很有帮助,建议大家好好看看。
四
再回到正题,下面是对Eyeriss处理器为例进行Benchmarking的结果。首先是处理器的spec和芯片整体的测试结果。这些需要指出的是,处理器的Spec在进行对比的时候也是很有必要的,是很多对比评价的基础信息。
然后是对Alexnet各个layer分解的测试结果。
最后还给出了用来评价FPGA的指标。
由于我们关注的是Benchmarking的指标设计,这里就不具体分析测试结果了。Eyeriss团队还设立了一个网站(http://www.rle.mit.edu/eems/dnn-benchmarking-form-2/),供大家提交自己的测试结果。在这个网站上可以下载相应的表格,也可以看到Eyeriss处理器的实例。
总的来说,由于DNN处理器的特殊性,比如对memorybandwidth的需求、DNN稀疏性的特点、MAC利用率问题等等,对于它做基准测试的时候很难简单的借用传统处理器的评价指标。我们需要综合性的或更有针对性的指标才能更好的表征DNN处理器的实际效能。Eyeriss团队提出一系列比较有针对性的指标,基本上能够覆盖了DNN处理器的各方面性能。不过这些指标能否以更简洁直观的形式表达,也是值得我们思考的问题。
五
Eyeriss团队总结的BenchmarkingMetrics,对于评价DNN处理器,甚至设计DNN处理器都很有启发。但是,他们使用几种DCNN网络(AlexNet,VGG16,GoogleNet,ResNet-50)作为Benchmark的方法是否合有效理呢?
首先,一个实际的问题是,要得到所有这几个网络在目标硬件上运行的数据,是一项巨大的工程,特别是对于小规模的研究团队来说。我们看到即使是Eyeriss处理器也只给出了AlexNet和VGG16的结果。实际上,这几种DCNN网络还是有不少相似之处的,用它们作为Benchmark,是否是做了很多重复和冗余的测试?
第二个问题是,这几种网络是否真正覆盖了各种DNN的需求。虽然Eyress更关注卷积层的处理,但FC/RNN/LSTM/GRU这类网络的应用也很广泛,在很多新出现非常有效的模型中,FC/RNN类型的层和卷积层经常是结合在一起使用的。对于这种情况,只用这几种以CNN为主的网络作为Benchmark是否有足够的代表性呢?如果还是采取把实际网络用作Benchmark的思路,我们就需要不断的扩大这个Benchmark的集合。显然这也是不可取的。
解决上述问题的一个思路就是「设计」新的Benchmark,就像Dhrystone这样的「SyntheticBenchmark」一样。下面我们就结合Baidu的DeepBench讨论一下「SyntheticBenchmark」的设计问题。
六
DeepBench项目[5]在百度众多的开源项目中受到的关注相对较少,不过他们对于DeepLearning硬件Benchmarking的讨论和实践,既是非常有意义的尝试,也是我们讨论Benchmarking问题的很好的参考。我们首先看看他们对项目目标的描述:
「TheprimarypurposeofDeepBenchistobenchmarkoperationsthatareimportanttodeeplearningondifferenthardwareplatforms.Althoughthefundamentalcomputationsbehinddeeplearningarewellunderstood,thewaytheyareusedinpracticecanbesurprisinglydiverse.Forexample,amatrixmultiplicationmaybecompute-bound,bandwidth-bound,oroccupancy-bound,basedonthesizeofthematricesbeingmultipliedandthekernelimplementation.Becauseeverydeeplearningmodelusestheseoperationswithdifferentparameters,theoptimizationspaceforhardwareandsoftwaretargetingdeeplearningislargeandunderspecified.」
「DeepBenchattemptstoanswerthequestion,"Whichhardwareprovidesthebestperformanceonthebasicoperationsusedfordeepneuralnetworks?".Wespecifytheseoperationsatalowlevel,suitableforuseinhardwaresimulatorsforgroupsbuildingnewprocessorstargetedatdeeplearning.DeepBenchincludesoperationsandworkloadsthatareimportanttobothtrainingandinference.」
上述文字中的一个关键词就是「basicoperation」,和Eyeriss团队直接用经典的DCNN网络作为Benchmark不同,DeepBench尝试使用基本操作而非完整网络模型来作为Benchmark。而另一个差别在于,Eyeriss团队主要工作在于设计Inference专用的硬件加速器,因此他们更关心Inference应用,而DeepBench则同时考虑Training和Inference的硬件评测问题。
下面这幅图是DeepBench在一个DeepLearning生态系统中的定位。
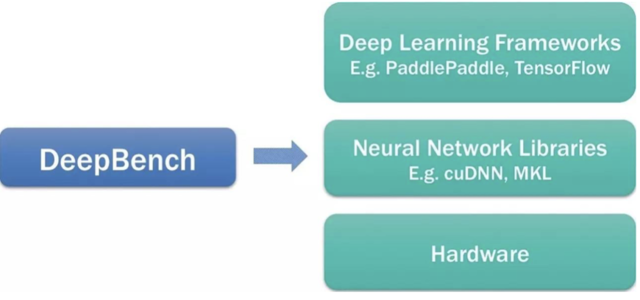
以下是他们对这个定位的说明:
DeepBenchusestheneuralnetworklibrariestobenchmarktheperformanceofbasicoperationsondifferenthardware.Itdoesnotworkwithdeeplearningframeworksordeeplearningmodelsbuiltforapplications.WecannotmeasurethetimerequiredtotrainanentiremodelusingDeepBench.Theperformancecharacteristicsofmodelsbuiltfordifferentapplicationsareverydifferentfromeachother.Therefore,wearebenchmarkingtheunderlyingoperationsinvolvedinadeeplearningmodel.Benchmarkingtheseoperationswillhelpraiseawarenessamongsthardwarevendorsandsoftwaredevelopersaboutthebottlenecksindeeplearningtrainingandinference.
可以看出,DeepBench试图设计更具普遍性的Benchmark,因此选择使用底层的操作(underlyingoperations)来评测在Training和Inference中的瓶颈问题。这实际上也是试图解决我们在上篇文章中提到的,「使用几个DCNN网络作为Benchmark是否具有普遍性?」这一问题。到这里,我们可以比较清楚的看到DeepBench的基本思路是设计类似Dhrystone这样的「SyntheticBenchmark」思路。
需要指出的是,DeepBench使用了硬件厂家提供的Library,比如Nvidia的cuDNN,Intel的MKL,还有ARM的ComputeLibrary。也就意味着它的「基本操作」是比这些Library封装的「基本操作」(比如矩阵乘法)的粒度要粗的,并且需要Library的支持。如果其它硬件厂商也想使用DeepBench,则也需要提供类似的Library(当然还包括一些porting的工作)。另外,它评估的结果实际是包括了目标硬件加Library的整体性能,而非单纯硬件本身。由于实际的应用者一般也是基于Library进行开发,所以这种方式也是合理的。但是,对于需要定位硬件设计问题或者瓶颈的人来说,使用这样的方法还需要考虑到Library对结果的影响。比如在DeepBench最新发布的时候,ARM的ComputeLibrary还只支持单精度浮点的卷积操作,不支持8比特定点;同时它也没有对RNN对的支持,这些功能限制对于测试效果的评估还是有比较大的影响的。
和Eyeriss提出了很多有特色的「BenchmarkingMetrics」不同,DeepBench的测试指标是比较简单的,主要就采用运行时间「Time(msec)」进行性能的评价。所以,我们对DeepBench的讨论主要还是集中于它设计的「测试程序」。
七
下面我们就具体看看DeepBench设计的用于Training和Inference的Benchmark。
对于Training,DeepBench从不同的应用模型(Source列)中总结出了一些特定的操作(TypeofOperations)。如下表所示:
其中最基本的操作包括三类:DenseMatrixMultiplication,Convolution,RecurrentLayers。这些选择是比较自然的,基本可以覆盖各种DNN的情况。最后一类All-Reduce是专门针对多GPU并行Training的场景。
对于每一种Operation,都有不同的参数。比如Converlution操作,就有如下的参数:W(input-time),H(input),C(channels),N(batchsize),K(numberffilters),R(filterwidth),S(filterheight),pad_hpad_w,VerticalStride,HorizontalStride,Platform(serverordevice),Forward,wrtInputs,wrtParameters。DeepBench对每种Operation都定义并且实现了多种不同的参数组合,反映各种应用中比较常见的配置(可以看作是一个测试内核Kernel)。具体的各种case大家可以看网站提供的Excel表格,以及Kernel的具体实现。
以下是Inference的主要操作和对应的一些典型应用(Source列):
对于Inference的BenchMark,除了基本操作以外DeepBench还讨论了以下几个问题。
DeploymentPlatform:分析了DNN模型部署在Server端(我们之前经常说的Cloud/Datacenter)和Device端(Edge/Embedded)的特点,也说明了DeepBench对不同的部署平台做了有针对性的测试。
InferenceBatchSize:分析BatchSize对于效率和延时的影响(BatchSize越大,并行处理的可能性阅读,实现效率越高,但处理延时也越大),以及在两者之间如何平衡。从DeepBench测试的结果来看,「在Server端采用4~5的batchsize,而在Device端采用1的batchsize是一个比较好的选择」。
InferencePrecision:讨论Inference精度的问题,以及DeepBech对精度选择的原因。
SparseOperations:分析稀疏性对inference性能的影响。一个有趣的结论是「基于我们的研究,与其密集模型基线相比,具有90至95%稀疏度的神经网络可以实现相对较好的性能。然而,当前实现的稀疏矩阵乘法主要是对更高的稀疏度(大约99%或更高)而优化的。通过包含稀疏内核(我们在上面的表格中看到的「SparseMatrixMultiplication」operation),我们希望激励硬件供应商和软件开发人员构建为90%至95%的稀疏性提供更好性能的硬件和库。」
MeasuringLatency:「许多Inference应用具有实时延迟要求。DeepBench定义的内核可以作为衡量单个操作的最佳延迟的起点。但是,考虑到基础操作不是完整的应用程序,测量全系统延迟不在本版本DeepBench的范围之内。」这里反映了使用基本操作作为测试程序的问题:无法统计整个实际应用程序(比如AlexNet)所花费完整时间。这是目前DeepBench面临的一个主要困难。在未来能否设计出更好的基本操作,并基于这些基本操作设计一些组合操作来模拟实际的应用程序,是值得研究的课题。
对于最后这个问题的讨论,也反映出SyntheticBenchmark设计的难度:如何通过「设计」,让不是真实应用的测试程序来准确「模仿」真实的应用,并得到能够反映现实世界情况的结果。从更大范围来看,随着DNN软硬件实现的不断优化,如何对其进行评价,验证和测试将会是我们一直要思考的问题。DeepBench是一个非常有益的尝试,希望未来还能看到更多更好的解决方案。
Reference:
[1]「TutorialonHardwareArchitecturesforDeepNeuralNetworks」,http://eyeriss.mit.edu/tutorial.html
[2]"BenchmarkingDNNProcessors",http://eyeriss.mit.edu/benchmarking.html
[3]"ComparingdensecomputeplatformsforAI",https://www.intelnervana.com/comparing-dense-compute-platforms-ai/
[4]Williams,Samuel;Waterman,Andrew;Patterson,David(2009-04-01)."Roofline:AnInsightfulVisualPerformanceModelforMulticoreArchitectures".Commun.ACM.52(4):65–76.ISSN0001-0782.doi:10.1145/1498765.1498785
[5]「DeepBench」,https://github.com/baidu-research/DeepBench
作者简介:唐杉博士先后在T3G(STE)、中科院计算所、紫光展锐(RDA)工作。具有15年以上的芯片设计经验,在3G/4G通信基带处理,专用处理器ASIP,多核SoC架构,ESL级设计和Domain-specific计算等方面有深入研究和实际经验。近一年来主要关注DeepLearning处理器和相关技术,现在Synopsys公司任职。公众号:StarryHeavensAbove。