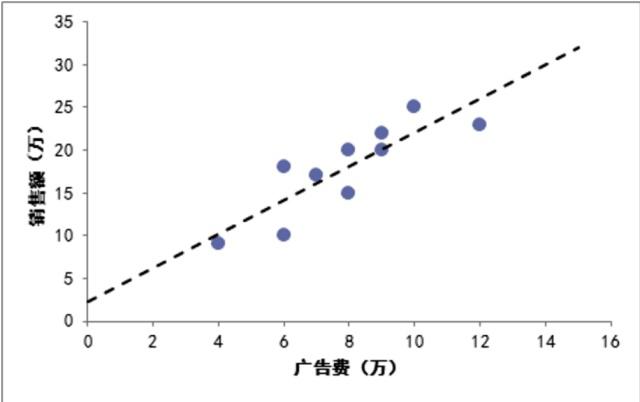
 图-广告费和销售额的拟合直线
图-广告费和销售额的拟合直线
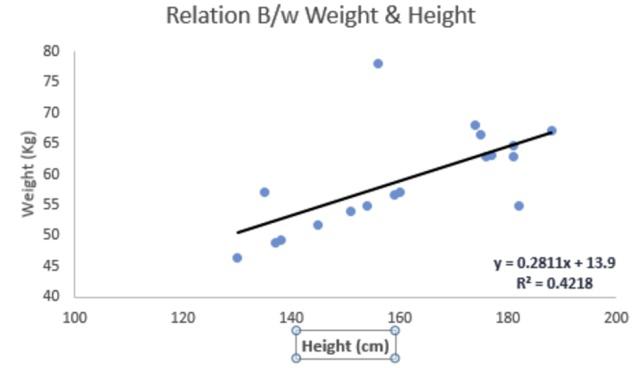 图-身高和体重的拟合直线多元回归有多个因变量和一个因变量,二者的关系是多维空间的平面,数据的分布或者在平面上,或者在平面下侧,或者在平面上侧:多元回归的向量方程回归过程描述
用一个很简单的例子来说明回归,这个例子来自很多的地方,也在很多的open source的软件中看到,比如说weka。大概就是,做一个房屋价值的评估系统,一个房屋的价值来自很多地方,比如说面积、房间的数量(几室几厅)、地段、朝向等等,这些影响房屋价值的变量被称为特征(feature),feature在机器学习中是一个很重要的概念,有很多的论文专门探讨这个东西。在此处,为了简单,假设我们的房屋就是一个变量影响的,就是房屋的面积。
假设有一个房屋销售的数据如下:
图-身高和体重的拟合直线多元回归有多个因变量和一个因变量,二者的关系是多维空间的平面,数据的分布或者在平面上,或者在平面下侧,或者在平面上侧:多元回归的向量方程回归过程描述
用一个很简单的例子来说明回归,这个例子来自很多的地方,也在很多的open source的软件中看到,比如说weka。大概就是,做一个房屋价值的评估系统,一个房屋的价值来自很多地方,比如说面积、房间的数量(几室几厅)、地段、朝向等等,这些影响房屋价值的变量被称为特征(feature),feature在机器学习中是一个很重要的概念,有很多的论文专门探讨这个东西。在此处,为了简单,假设我们的房屋就是一个变量影响的,就是房屋的面积。
假设有一个房屋销售的数据如下: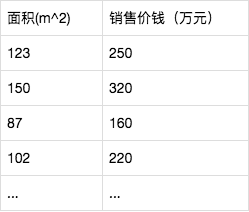 这个表类似于帝都5环左右的房屋价钱,我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:房屋销售xy直线如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:
这个表类似于帝都5环左右的房屋价钱,我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:房屋销售xy直线如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子: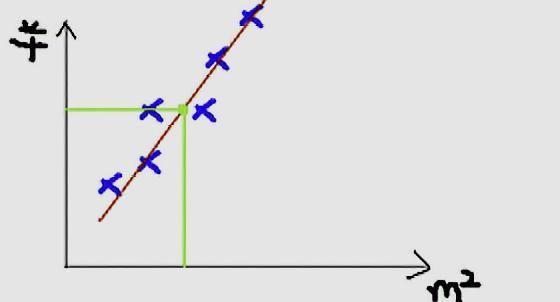 数据预测绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号,在不同的机器学习书籍中可能有一定的差别。房屋销售记录表 - 训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x房屋销售价钱 - 输出数据,一般称为y拟合的函数(或者称为假设或者模型),一般写做 y = h(x)训练数据的条目数(#training set), 一条训练数据是由一对输入数据和输出数据组成的输入数据的维度(特征的个数,#features),n下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。机器学习的过程我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:一维线性回归函数θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:线性回归函数向量表示函数我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数\(error function\),描述h函数**不好**的程度,在下面,我们称这个函数为J函数在这儿我们可以做出下面的一个错误函数:
数据预测绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号,在不同的机器学习书籍中可能有一定的差别。房屋销售记录表 - 训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x房屋销售价钱 - 输出数据,一般称为y拟合的函数(或者称为假设或者模型),一般写做 y = h(x)训练数据的条目数(#training set), 一条训练数据是由一对输入数据和输出数据组成的输入数据的维度(特征的个数,#features),n下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。机器学习的过程我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:一维线性回归函数θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:线性回归函数向量表示函数我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数\(error function\),描述h函数**不好**的程度,在下面,我们称这个函数为J函数在这儿我们可以做出下面的一个错误函数: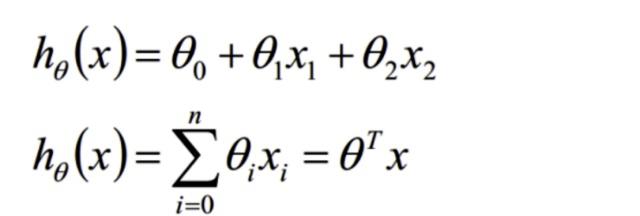 损失函数这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
总结:
本章主要是认识线性回归的基本术语和基础模型,机器学习不是一个曲高和寡的东西,它是将我们常用数学知识运用到工业、生活中,从而具备预测、分析的能力,希望借此降低我们的心里认知,走向机器学习。
损失函数这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
总结:
本章主要是认识线性回归的基本术语和基础模型,机器学习不是一个曲高和寡的东西,它是将我们常用数学知识运用到工业、生活中,从而具备预测、分析的能力,希望借此降低我们的心里认知,走向机器学习。