为什么每个人都需要有模型思维?
模型思维
预测是基于经验和知识而展开的活动,是一个根据已知条件和知识,寻求未知事物的过程。因此,准确的预测离不开丰富的经验和知识。但是预测也作为一种独立的思维活动,有一些相应的方法论。我们可以通过一些方法提高预测的准确性。
最有助于预测的方法论是建模思维。模型是基于实际问题或者客观事物的经验和规律,进行抽象、概括和总结而成的。[1]它被创造出来就是为了分析事物之间的关系、解决特定的问题,以及预测事物发展。
我们用几道数学题来帮助大家了解模型对我们预测的重要性。
在三角形 ABC 中,∠A=90°,∠B=60°,请问∠C 是多少度?
我想大家都会很快算出 ∠C=30°。因为我们都学过:三角形内角之和等于 180°。在这里「三角形内角之和等于 180°」,这就是一个模型,一个帮助我们根据已知,预测未知的模型。只不过这种预测,结果比较单一和稀疏平常,以至于大家不认为这是一种预测。
那么接下来,我们用另一道题目帮助大家理解模型和预测。
某城市拥有本地人口 1400 万人,预计该城市未来每年流入人口约 15 万人,该城市 10 年后会有多少万人口?
比起前面的问题,这个问题更贴近生活,也更有预测的味道。在这个问题中,我们运用到的就是线性函数模型。我们假设十年口的人口为 Y,年数为 X,那么每年的人口变化为:Y=1400+15X。将 X=10 带入,得出 Y=1550。
预测越复杂的事物和问题,我们需要运用的模型就会越复杂,所需要加入的变量会越多,假设条件一般也会越多。
在预测群体的智力时,我们会用到正态分布模型;在预测生物繁殖速度时,我们会用到指数模型;在预测污染物扩散时,我们会用到高斯模型;在预测传染病传播时,我们会用到传染病传播模型;在预测产品的价格和购买量的关系时,我们会用到供需模型;在预测重金属衰变后的含量时,会用到半衰期模型……
我们在前面已经提及到了如何寻找事物之间的因果关系,但是寻找因果只是一种定性的判断。模型的价值则是对这种定性关系进行一种定量分析。我们可以通过模型更具体,更详尽地了解这种因果关系。
定性预测:因果
定量预测:模型
举个例子,我们想要对大气污染物扩散进行预测和控制。我们可以大抵知道「风速越大,污染物的扩散越快」。这里是一个定性的因果判断。而大气扩散高斯模型可以让你看到风速和污染物扩散速度之间的函数,甚至可以让你知道污染物的落点在哪些范围内。这种模型的定量预测能够给我们带来更大的价值。
定性预测:风速越大,污染物的扩散越快
定量预测:

在具有衰变性质的元素的测量也是如此。如果我们不清楚半衰期的概念,我们只能说「这些元素的含量会随着时间的推移而减少」。这是一种非常粗糙的定性因果关系。而我们通过总结和归纳,分析出元素的半衰期,那么我们就可以运用半衰期模型,更精准地预测某些物质的含量。比如,碳十四的半衰期是 5730 年左右,我们就能够构建函数来分析这一元素未来的变化,甚至可以运用这种规律进行考古研究。
定性预测:这些元素的含量会随着时间的推移而减少
定量预测:N(t)=N0e-λt (其中 N0 初始元素含量,e 为自然对数,λ 为衰变常数)
模型的价值在于,将粗糙的定性关系转变为更准确的定量关系。如果我们想要更好地预测事物的发展规律,就必须时刻保持建模的思维。
而想要给事物建立一个预测模型,我们必须先确定或者假设因果。这里的因果需要我们根据生活现象或者数据等方式,做一个初步的判断。这里的假设和判断不一定是正确的,因为我们后面可以通过一些方法评估这一个推测的结论。
接下来,我们要确定因素。什么作为影响因素,什么作为想要预测的因素,还有哪些是会影响预测的其他因素。然后,我们要收集数据,根据数据之间的关系,寻找比较适合这一因果假设的模型。最后,将这个模型应用到实际中去,通过真实反馈来评估这一模型的可靠性。如果出现了较大的偏差,我们还需要修正模型。
我们采用一个比较简单的例子作为建模思维的引例,帮助大家加深对建模过程的理解和掌握。
对数据做初步观察,我们可以大概感知到,这个新兴行业的发展随着时间蒸蒸日上,不过具体的增长幅度和变化趋势,我们还需要通过数据建模的方式来评估。
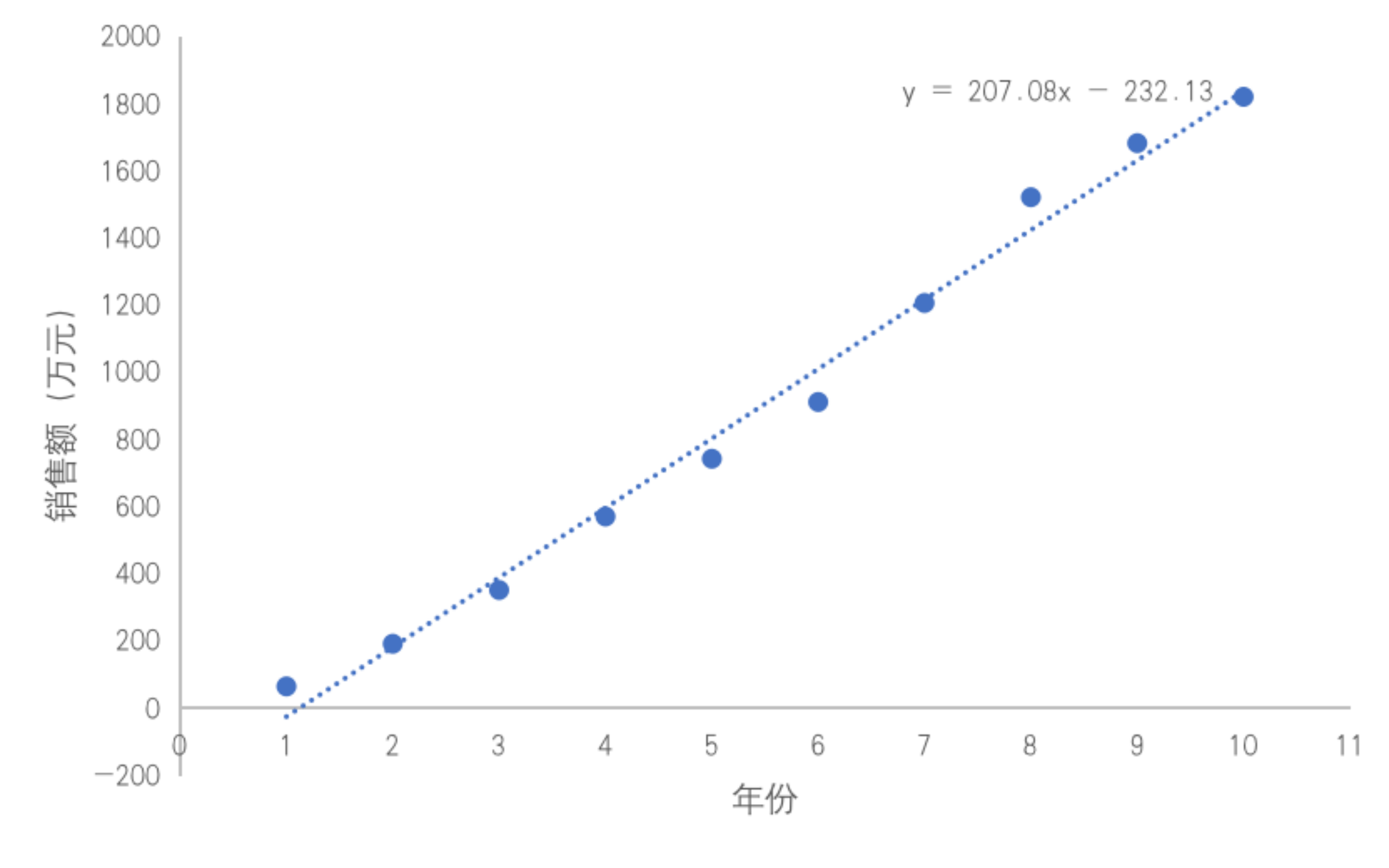
图 1 某新兴领域市场销售额变化图
我们将数据放进坐标轴中,然后用在初中就学习过的的线性回归知识,或者借用 Excel 软件,可以算出它们之间的关系:y = 207.08x - 232.13, 得到了图 3-1 中的函数关系。然后带入 x=11,得到 y=2045.75。最后, 我们预测, 该新兴行业第十一年的销售额为 2045.75 万。
但是, 我们也要意识到一个行业的增长不可能一直持续,我们需要评估用一元一次线性回归的方式来预测是否合理。如果接下来数据结果的偏差很大, 我们很可能需要用其他的函数模型来做预测。比如,用对数函数的模型来预测接下来的销售额。
在这个建模的例子中,我们先根据数据情况得到了一个模糊的感知,然后再利用模型确认两者的函数关系,进而预测未来的销售额情况。同时,我们还需要结合实际情况,评估是否需要对模型进行修正。
除了线性模型,常用的函数模型还有正态分布、指数分布和对数分布。这些分布曲线可以让我们预知非常多的生活现象。
在网上经常会看到一些关于收入的内容,看多了会对这个世界产生偏差, 以为遍地都是百万富翁。那我们问一个问题, 请问我国有多少年入百万的人?如果我们懂得正态分布模型,结合两三个可以查阅到的数据, 这个数值是可以评估出来的。
我们结合高中的数学知识, 大抵知道正态分布的函数关系,以及在坐标轴上的表现。如下:
其中, 数学期望为 μ, 标准差为 σ
图 2 正态分布 ±4𝜎 的部分,以及各个标准差所占的百分比
已知人群的收入基本符合正态分布, 即使我们假设人们的年平均收入为 10 万, 标准差为 5 万,大于 25 万元的可能性已经只剩下 0.13%。实际上,在中国家庭金融调查和中国社会综合调查的数据比对中,年入百万以上的比例约为万分之五。
通过简单的正态分布模型, 我们就减少了被表象迷惑的可能性。在其他模型上也是如此, 它们都可以用来预测特定领域的事物。这类定量的推理比起各种奇闻轶事,小道消息更接近现实世界。
关于事物的预测模型的种类非常多, 可能多达上万种。人类的每一门学科都有成千上万的预测模型,作为我们了解特定领域的工具。因此我们很难全部掌握。但是,对于其中一些常见的、重要的、客观的、以及具有广度和深度的模型,可以作为我们重点学习的对象。
斯科特·佩奇(Scott Page)在《模型思维》一书中做了一些关于思维模型的阐述。[1]他在书中总结了 28 个重要的思维模型, 这些模型可以解释生活中的大部分现象和问题。
随机游走模型可以解释,即使是胜率为 50% 的赌博, 赌徒依旧会输得倾家荡产;博弈论模型可以预测,人们在什么情况下选择合作, 什么情况下选择竞争;信息论模型可以帮助你, 用尽可能小的代价找出问题所在;阈值模型可以帮助你预测在哪些情况下, 可能出现难以承受的问题……
我认为大家可以去了解这些模型, 这对我们理解事物有非常大的帮助。这就像文案设计师先设计一些模板,当后面遇到类似的设计工作时,只需要往模板上简单得修改。这种方式大大提高了设计师的工作效率。同样的, 当我们需要思考生活现象时,这些模型可以让我们更快看到其内在机制和工作原理,提高思考的效率。
关于预测的模型非常多, 本书不做一一介绍。对这些模型感兴趣的读者可以阅读《模型思维》一书,相信这本书会给你很大的启发。
【本篇故事完结】