各位小伙伴们,今天我要和大家分享一个困扰了我很久的问题的解决方案 —— 如何高效地合并多个Excel表格。我相信很多人都遇到过这样的情况:手头上有好几个相似结构的Excel表格,需要将它们合并成一个大表格进行统一分析。这个看似简单的任务,如果表格数量多、数据量大,往往会变得非常耗时耗力。
经过一段时间的研究和实践,我终于找到了几种高效的解决方案。今天,我就把这些方法分享给大家,希望能帮助到同样有这种需求的小伙伴们。
方案一:一键表格合并助手
首先,我要隆重介绍一下我最近开发的一款神器 —— "一键表格合并助手"。这个工具是我根据自己的实际需求开发的,旨在解决大家在合并表格时遇到的各种痛点。
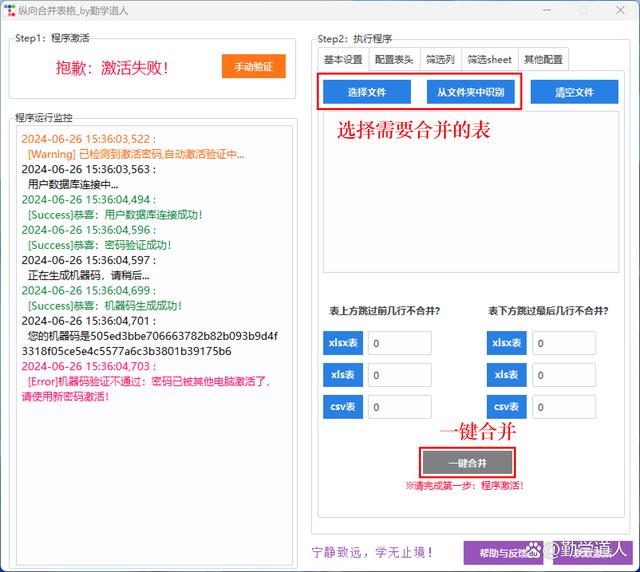
优势:
操作简单:界面直观,无需编程知识,真正做到一键合并。
性能强劲:采用多线程技术,能够快速处理大量表格。
功能全面:支持多种文件格式,可处理表头不一致的情况,还能自动去重。
大数据处理:基于Python开发,轻松应对千万级数据量。
劣势:
需要下载安装:不像Excel那样随时可用,需要额外安装。
可能需要一定学习成本:虽然操作简单,但新功能可能需要稍加熟悉。
使用步骤:
打开软件,选择需要合并的表格文件。
设置合并参数,如是否需要去重、是否添加数据来源列等。
点击"开始合并"按钮,等待处理完成。
选择导出格式,保存合并后的文件。
这个工具的特色在于它不仅能处理常规的合并需求,还能应对一些复杂情况。比如,它可以智能识别意义相同但名称略有不同的表头,自动跳过空白列和说明行,甚至还能自定义合并的列和sheet。对于需要经常处理大量表格数据的朋友来说,这无疑是一个极大的效率提升。
想要玩一下这个工具,点点赞、点点关注找我要一下哦
视频演示:视频最后有领取方法
方案二:Excel Power Query
接下来,我要介绍的是Excel自带的一个强大功能 —— Power Query。这个工具其实藏在Excel里很久了,但很多人可能还不太熟悉。
优势:
无需额外安装:Excel自带功能,随时可用。
操作相对简单:有图形界面,比编程更易上手。
可重复使用:创建的查询可以保存,下次使用时只需刷新数据。
数据处理能力强:不仅可以合并表格,还能进行各种数据清洗和转换。
劣势:
性能限制:对于超大型表格(如千万级数据),处理速度可能不如专门的工具快。
学习曲线:虽然比编程简单,但完全掌握还是需要一定时间。
使用步骤:
打开Excel,切换到"数据"选项卡。
点击"获取数据" > "从文件" > "从文件夹"。
选择包含所有需要合并的Excel文件的文件夹。
在打开的Power Query编辑器中,选择"合并文件"。
选择要合并的表格和列,点击"确定"。
根据需要进行数据清理和转换。
点击"关闭并加载",将合并后的数据导入Excel。
Power Query的优势在于它不仅能完成简单的表格合并,还能进行复杂的数据处理。比如,你可以在合并过程中添加自定义列、筛选数据、更改数据类型等。而且,一旦设置好查询,以后只需点击"刷新"就能自动更新数据,非常方便。
方案三:Python脚本
作为一名数据分析爱好者,我也忍不住要推荐使用Python来处理表格合并的任务。虽然这需要一定的编程基础,但它的灵活性和强大的数据处理能力是无可比拟的。
优势:
极高的灵活性:可以根据具体需求自定义合并逻辑。
强大的数据处理能力:可以轻松处理各种复杂的数据情况。
高效率:对于大量数据,Python的处理速度通常比Excel快得多。
可扩展性强:可以集成其他数据分析和可视化库,如matplotlib、seaborn等。
劣势:
需要编程基础:对于完全的编程新手可能有一定门槛。
需要安装Python环境和相关库。
没有图形界面,对非技术用户不够友好。
下面是一个简单的Python脚本示例,用于合并同一文件夹下的所有Excel文件:
import pandas as pd
import os
# 指定包含Excel文件的文件夹路径
folder_path = 'path/to/your/folder'
# 获取文件夹中所有的Excel文件
excel_files = [f for f in os.listdir(folder_path) if f.endswith('.xlsx')]
# 创建一个空的DataFrame来存储合并后的数据
merged_data = pd.DataFrame()
# 遍历所有Excel文件并合并数据
for file in excel_files:
df = pd.read_excel(os.path.join(folder_path, file))
merged_data = pd.concat([merged_data, df], ignore_index=True)
# 将合并后的数据保存到新的Excel文件
merged_data.to_excel('merged_file.xlsx', index=False)
print("合并完成!")
这个脚本使用了pandas库来读取和处理Excel文件。它会自动识别指定文件夹中的所有Excel文件,将它们合并到一个DataFrame中,然后导出为一个新的Excel文件。
使用Python的好处是,你可以根据需要轻松地修改和扩展这个脚本。比如,你可以添加数据清理的步骤、进行复杂的数据转换,甚至可以集成数据可视化,一次性完成从数据合并到分析报告生成的全过程。
总结一下,这三种方法各有特点:
"一键表格合并助手"适合需要频繁处理大量表格的用户,操作简单,性能强大。
Excel Power Query适合熟悉Excel的用户,无需额外安装,适合中小型数据量的处理。
Python脚本则适合有编程基础、需要高度自定义处理逻辑的用户,特别是在处理超大规模数据时更有优势。
选择哪种方法,主要取决于你的具体需求和技术背景。如果你经常需要处理大量表格,而且不想花太多时间学习编程,那么我强烈推荐试试"一键表格合并助手"。它能满足大多数人的需求,而且使用起来非常方便。
最后,我想说的是,数据处理的世界博大精深,远不止这三种方法。随着大家的技能不断提升,相信你们会发现更多有趣和高效的数据处理方法。如果你有其他好用的表格合并方法,也欢迎在评论区分享出来,让我们一起进步!
对了,如果你觉得这篇文章对你有帮助,别忘了点赞、收藏哦!你们的支持是我继续创作的动力。如果对文中提到的工具或方法有任何疑问,也欢迎在评论区留言,我会尽快回复的。
最后,我想请教大家一个问题:你们平时最常遇到的数据处理难题是什么?欢迎在评论区分享,没准儿你的问题就是我下一篇文章的主题哦!