昨天开始回归系列的第一篇,是最简单的一元线性回归。除了线形关系,还有各种非线性关系,比如指数关系、对数关系、多项式关系,这些都要使用对相应的数据变换后才能进行分析。今天就从对数分析开始,来进行演示说明。很多具体的参数和判别方式和昨天的一元线形回归一样,这一篇就不赘述了。
对数回归是一种非线性回归模型,它假设因变量和自变量之间存在对数关系。与线性回归不同,对数回归利用对数函数来捕捉自变量与因变量之间的非线性关系。通过对数变换,我们可以将原本的非线性关系转化为线性关系,从而使用线性回归的方法进行建模和分析。
对数回归的基本形式可以表示为:y=a+b⋅ln(x)。
import pandas as pd
import numpy as np
np.random.seed(0)
广告费用 = np.random.exponential(scale=100, size=100)
销售额 = 50 + 15 * np.log(广告费用) + np.random.normal(scale=5, size=100)
data = pd.DataFrame({'广告费用': 广告费用, '销售额': 销售额})

在做分析之前,先通过可视化原始数据和对数变换后的数据,帮助理解数据的分布和关系↓
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import seaborn as sns
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x=data['广告费用'], y=data['销售额'])
plt.title('原始数据')
plt.xlabel('广告费用')
plt.ylabel('销售额')
data['Log_广告费用'] = np.log(data['广告费用'])
plt.subplot(1, 2, 2)
sns.scatterplot(x=data['Log_广告费用'], y=data['销售额'])
plt.title('Log-Transformed Data')
plt.xlabel('Log of 广告费用')
plt.ylabel('销售额')
plt.tight_layout()
plt.show()
从图形可以清晰的看到,左边是原始数据的分布,呈指数分布;右边是变换后的效果,整体呈线形分布。
接下来就使用转换后的数据进行线性回归的模型构建。昨天介绍两种方法,今天这里就直接使用statsmodels来实现,更简单,且模型判断参数更丰富↓
import statsmodels.api as sm
# 定义自变量和因变量
X = sm.add_constant(data['Log_广告费用'])
y = data['销售额']
# 拟合模型
model = sm.OLS(y, X).fit()
# 输出模型摘要
print(model.summary())
几个重要的参数:R方是0.939,调整R方是0.938。说明模型的拟合效果还是很好。Prob (F-statistic)接近0,模型整体显著;P值(P>|t|)接近0,模型参数也显著。整体来说模型效果很不错。绘制一下拟合后的图形↓
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x=data['广告费用'], y=data['销售额'])
plt.plot(data['广告费用'], model.predict(sm.add_constant(np.log(data['广告费用']))), color='red')
plt.title('原始数据拟合线')
plt.xlabel('广告费用')
plt.ylabel('销售额')
# 拟合效果图(对数变换数据)
plt.subplot(1, 2, 2)
sns.scatterplot(x=data['Log_广告费用'], y=data['销售额'])
plt.plot(data['Log_广告费用'], model.fittedvalues, color='red')
plt.title('对数变化拟合曲线')
plt.xlabel('Log of 广告费用')
plt.ylabel('销售额')
plt.tight_layout()
plt.show()
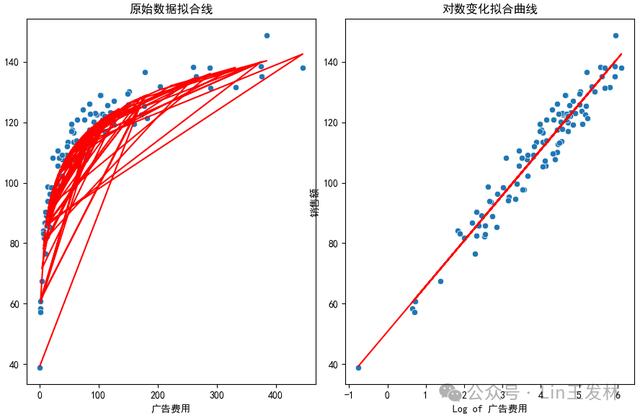
看上去效果也不错。
接下来就可以使用模型对数据进行预测了,我们先生成需要预测的数据集↓
# 生成新的广告投入数据
new_广告费用 = np.random.exponential(scale=100, size=20)
new_log_广告费用 = np.log(new_广告费用)
# 创建新的DataFrame
new_data = pd.DataFrame({'广告费用': new_广告费用, 'Log_广告费用': new_log_广告费用})
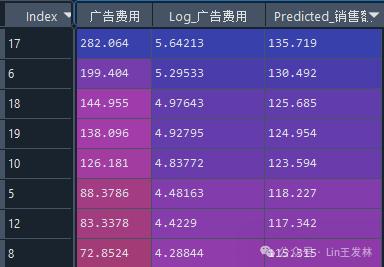
因为模型是对数变换后的,所以预测的输入变量也需要进行对数变换,最终结果如下↓
# 预测销售额
new_data['Predicted_销售额'] = model.predict(sm.add_constant(new_data['Log_广告费用']))
End